-
Data collection rule creation
- Visualization of collection rules for data collection (rule-based collector)
- The simulator replicates the user's online browsing patterns while simultaneously gathering data.
-


It can collect any data you want.
SCRAPING STUDIO is a reputable and powerful big data collecting tool that gathers a ton of data from the web in real time to analyze it and draw conclusions from a variety of industries. High-quality data can be collected without geolocation or language constraints.
- #DeepWeb collection
- #Social data collection
- #VOC collection
- #Market and trend analysis
- #Quality management of collected data


What Makes SCRAPING STUDIO So Special?
SCRAPING STUDIO leverage distributed processing technology to enable real-time collection of vast amounts of data. Data from the DeepWeb and SNS are also gathered in addition to data from the general web, and the quality of the data is managed by using quality verification tools to automatically discover and categorize issues.
-
Point 01
Hyper-scale
data collection architecture

-
Point 02
Automatic collection of
and social data

-
Point 03
Scenario-based
data collection and structuring

-
Point 04
Verification tool to assess the
of the collected data

-
Point 05
to assess the quality of the collected data Point 05 Data collection using
user devices

System Configuration

Core Technology
- Various big data collection
- Deep web scraping
- Automation of collection quality control
- Large-scale hybrid data collection
Various big data collection
Collection technology that covers general web to deep web, documents to multimedia
You may use a range of collecting methods, including scenarios, RSS, and Open API-based, to gather the data you need, including professional data, SNS, deep web data that requires authentication, text, and multimedia.
Features
-
01Deep web data collection
It is able to gather content from specialized websites that require login, such as academic journals and papers.
-
02Social data collection
It gathers a range of social data needed for social listings from sites including Facebook, LinkedIn, YouTube, Twitter, and Naver and provide scheduling and status check of the collection target.
-
0303 Multimedia data collection
In addition to text data, file data such as PDF, DOC, XLS, and multimedia such as images and videos can be collected.

-
04Meta search collector
The meta-search collector collects the latest data from around the world using search results from famous search engines such as Google, Nate, Naver, Daum, and Bing.

Deep web scraping
Data collection and quality verification based on user’s dynamic events
Data can be collected based on action rules of dynamic events, such as mouse clicks, scrolls, and logins, and evaluate and verify the quality of the collected data through pre-simulation. Validated data can be stored directly into the database through content parsing to increase data utilization. 특장점
Features
-
01Scraping of dynamically generated contents
It can gather dynamically created content, such logins and AJAX, enabling users to gather the most recent information that occasionally changes.

-
02Collection simulator applied with user actions
Simulated user actions, including as mouse clicks, scrolling, keyboard input, and logins, can be used to collect data.

-
03Data analysis and DB conversion
Using content parsing (analysis) rather than HTML, it can immediately transform data into a database after scraping it.

-
04Quality assessment through pre-simulation
The collection policy gives the ability to assess and confirm the accuracy of the data through pre-simulation.

Automation of collection quality control
Issue management of collected data through management dashboard for real-time collection status monitoring
To reduce mistakes in data collection and guarantee the highest level of quality, it automatically detects anomalies during data collection and offers an automated debugging collaboration mechanism for errors.
Features
-
01Automatic detection of abnormal signs and statistical management
The dashboard's real-time data collection monitoring provides integrated management features like automated error detection and collecting statistics.

-
02Management of collection error and debugging collaboration system
A systematic error management process allows users to track various issues that arise during data collection and quickly solve them.

Large-scale hybrid data collection
Three infrastructure options and issue response systems that are customized for user environment
Three infrastructure options: on premise/hybrid cloud/multi-cloud are offered. They can be tailored to customer environments and are equipped with issue response systems such as IP blocking and errors for uninterrupted data collection.
Features
-
01Cloud-based deployment and operation
Using Kubernetes and Docker, it's easy to build and operate on multiple cloud computing platforms, including Google and Amazon Cloud.

-
02Automatic load management and auto-scale out
Depending on the workload status, the infrastructure for data collecting can automatically increase or decrease resources.

-
03Automatic repositioning of collected resources
The data collector is instantly relocated to another server to reduce faults when problems arise, such as IP blocking and server errors.

SCRAPING STUDIO TOOL
Tool for creating data collection projects, monitoring data collection, and quality control
-
Data collection workbench

-
Integrated management

-
System monitoring notice

-
Data collection statistics report

-
Data quality management

-
Data source management

Tool Introduction
-
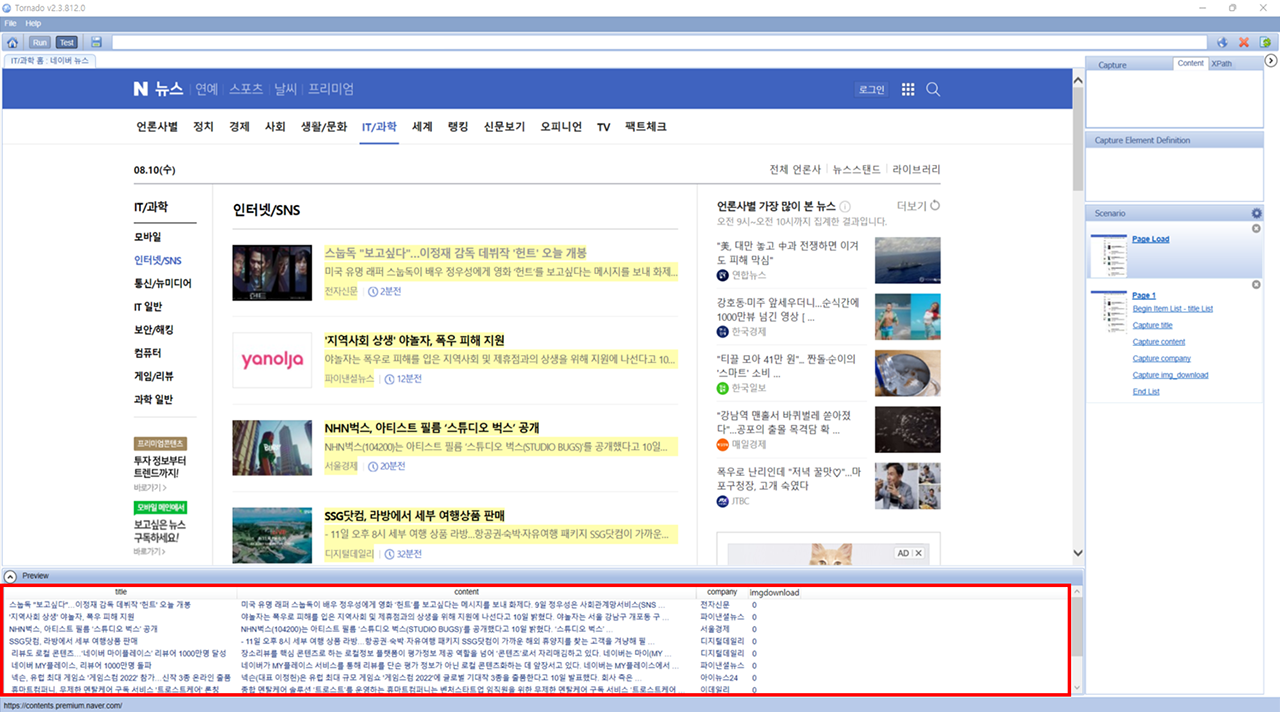
01Data extraction collection workbench
-
02Integrated management of data collection operations
-
Management/request for data collection project and operation management for tests
- Manage data extraction projects (Checks collection project lists )
- Manage data extraction projects (Create new collection projects )
- Manage data collection projects
- Manage data collection projects
- Manage data collection tasks (Assign and select tests, check lists )
- Schedule data collection (Once/daily/weekly/monthly/custom )
-
-
-
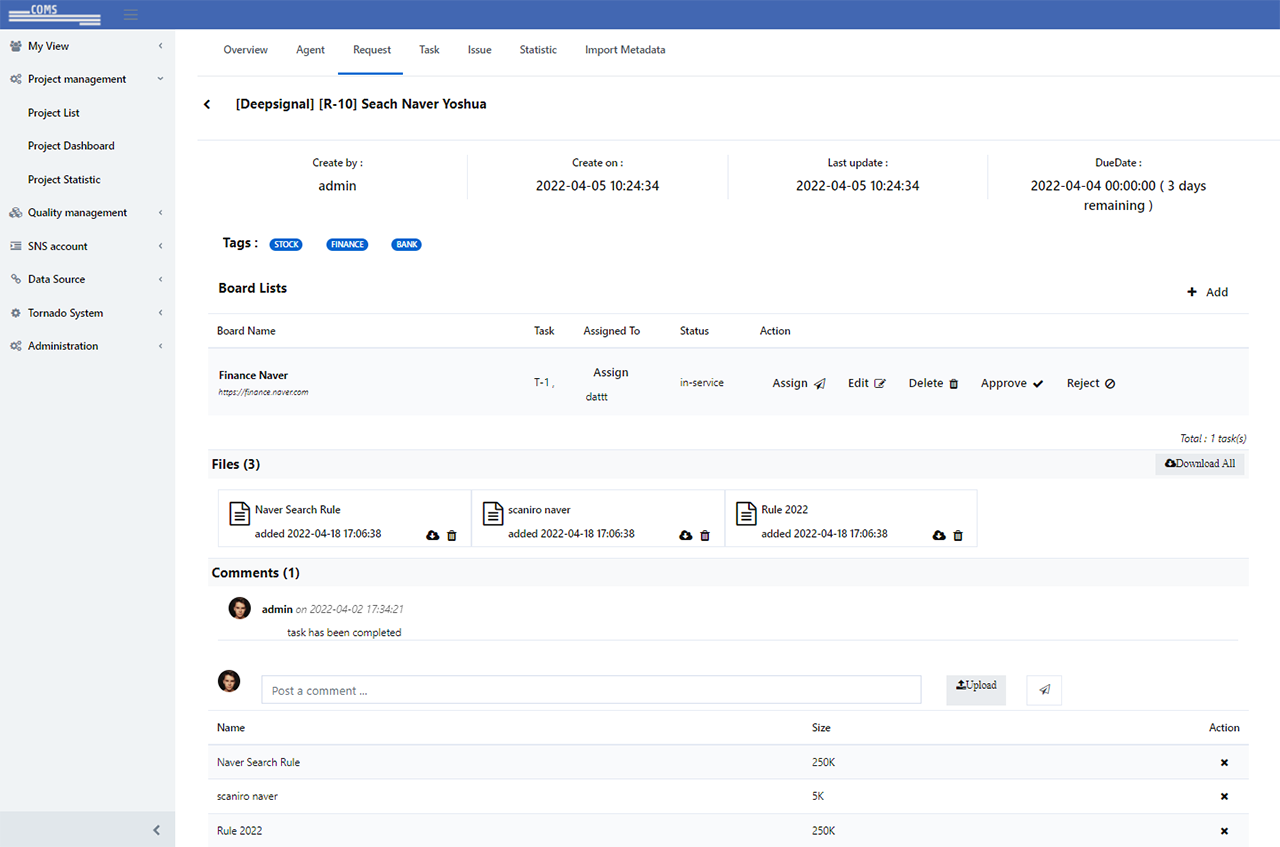
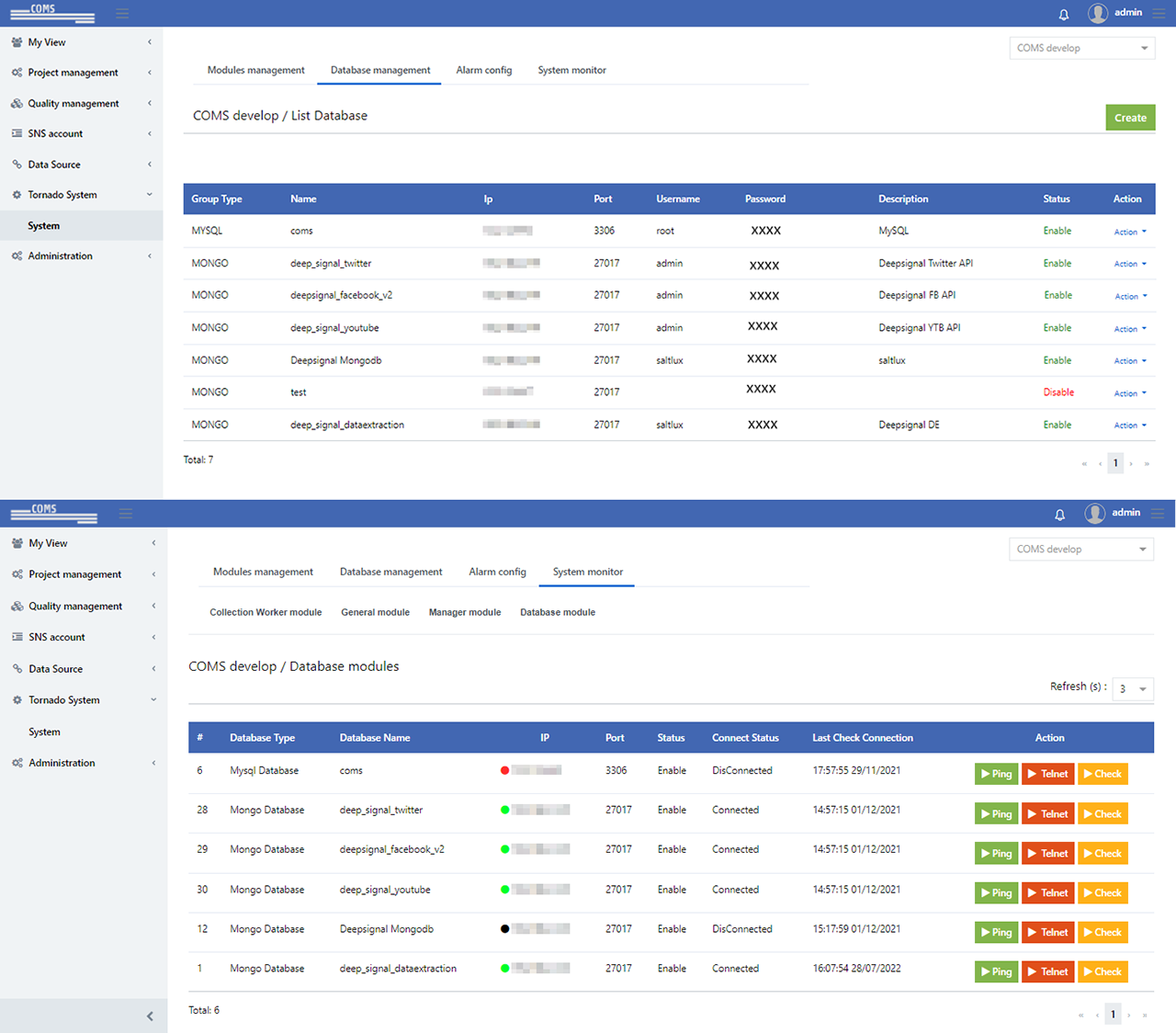
03System monitoring and notices
-
Manages and monitors collection system and database, sends out notices.
- Database management list (Checks database list )
- Database management list (Set up and modify database connections )
- Database monitoring list (Checks database list and status )
- Database monitoring list (Checks database and status )
- Manage notice settings (Create new notice )
- Manage notice settings (Set notice type when an event occurs )
-
-
-
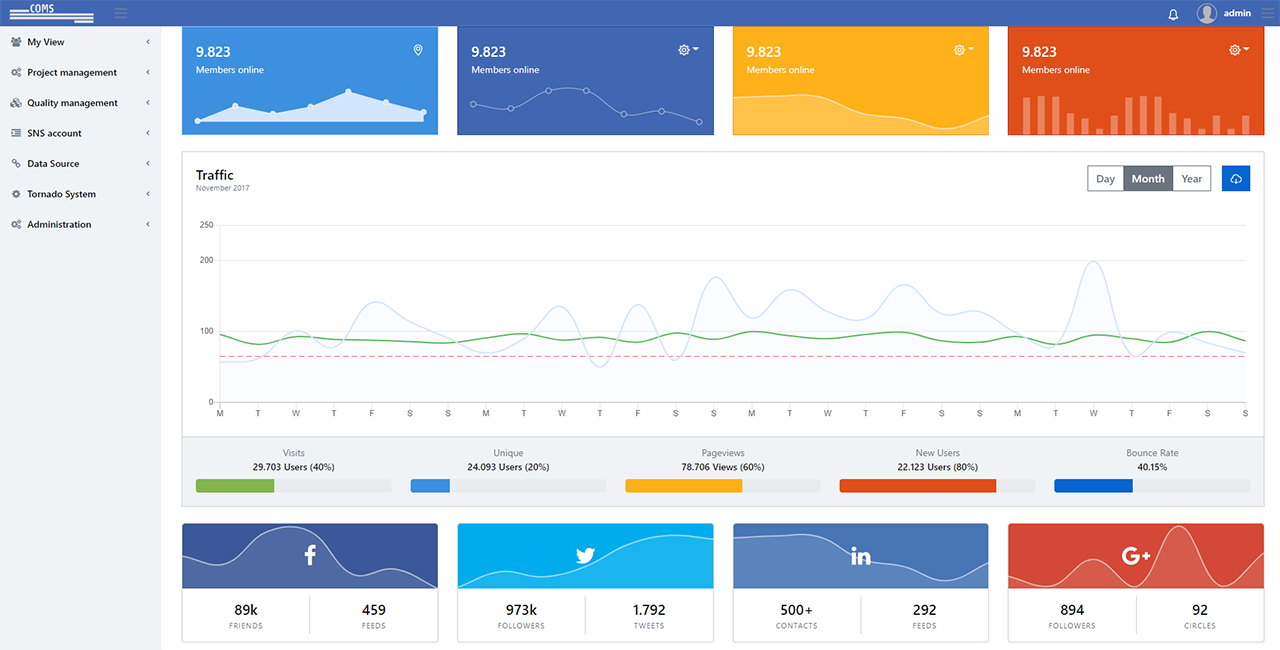
04Data collection and statistics report
-
Manage status and statistics of collected data
- Provision of data collection statistics by date
- Provide detailed data collection statistics by running type
- Automatically sends email reports
-
-
-
05Data quality management
-
Data quality control through issue tracking and collaboration
- Automatic identification/reporting of frequent collection errors/changes to the target collection site during collection
- Overview of issue status
- Issue management process through collaboration and by assigning a manager
- Manage issue tracking and status list of issue management
-
-
Success Story
-
External data collection
Defense IT fusion technology and anomaly analysis
Collected, refined, and provided solutions for real-time analysis of deep web data that cannot be recovered from countries like the United States, Russia, China, or North Korea.
-
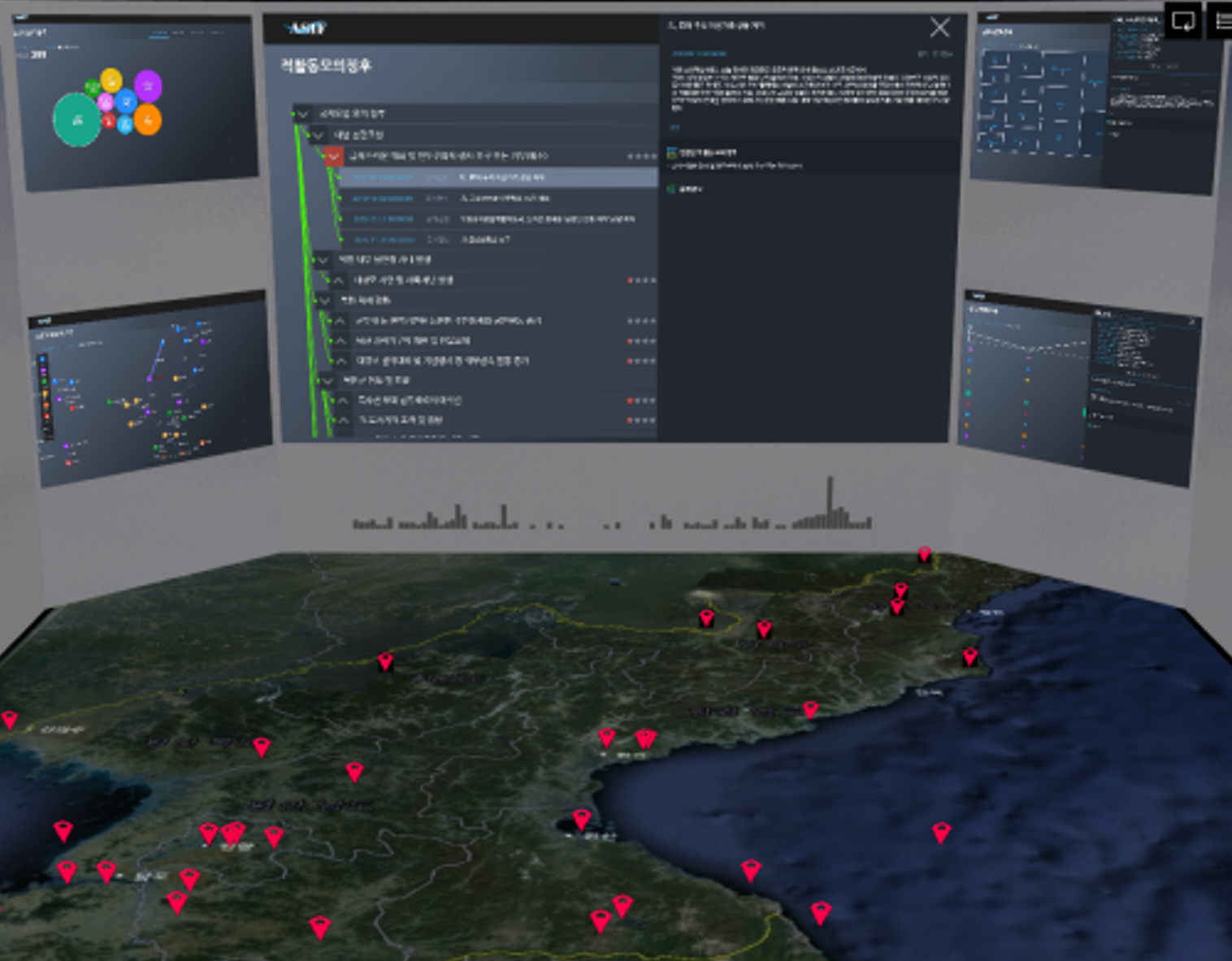
- Defense and security crisis identification and early response using data-based inference and prediction technologies
-
External data collection
Large-scale global multichannel data collection
Collected on-demand data from over 1500 different channels worldwide for customer needs analysis and real-time risk monitoring
-

- Enhanced customer satisfaction and market competitiveness with active market sensing using external data from multi-channels
-
External data collection
Collection of product information and financial information to secure market competitiveness
Gathered financial product-related data such as product information and interest rate information on domestic financial sites
-

- Compared products from other financial companies using financial product-related data and strengthened market competitiveness
Reference
-
Data collection
Constitutional Court
Continuous collection of legal information, provision of up-to-date cases and legal information

-
Data collection
Korea Culture Information Service Agency
Collection of cultural information and private cultural information of the Ministry of Culture, Sports and Tourism and each government department

-
Data collection
Kotra
Integrated platform for information on import/export of the foreign economy

-
Data collection
Data collection KITA
Collection and analysis on trade support business data for each institution to provide information

-
Data collection
MOGEF
Social data collection

-
Data collection
Korea Maritime Safety Tribunal
system for providing marine safety and accident-related public information

-
Data collection
Korea Electric Power Corporation
Collection and analysis of power-related social data

-
Data collection
Ministry of Food and Drug Safety
Predictive-based big data collection for food accidents
